1. 前言
本文将会从上下文无关文法开始介绍,从使用 BNF 描述语法到理解递归下降分析思想,最后实现一个简单的 html 解析器收尾。本文的亮点是使用 typescript 编写组合子编译器,对于前端开发某些特定领域会有重要意义和价值。同时本文注重实用价值,配合简短 js 代码示例来帮助理解。
2. 巴科斯范式 - 语法描述语言
巴科斯范式 Backus Normal Form,缩写为 BNF, 是一种用于表示上下文无关文法的语言。
BNF 每一行是一个推导规则(产生式),格式为:
<符号> ::= <表达式>
这里的 <符号> 是非终结符,表达式由一个符号序列,或用竖杠 '|' 分隔的多个符号序列构成,例如:
例如字符串的 bnf:
STRING ::= '"' TEXT '"'
| "'" TEXT "'"
字符串可以是双引号的也可以是单引号的。
左边的 STRING 是非终结符,右侧的引号"是终结符,TEXT 是非终结符因为它还能继续展开,例如:
TEXT ::= (letter | digit)*
每个非终结符都能被右侧的符号序列替换,即上下文无关。从未在左端出现的符号叫做终结符。
使用 BNF 描述一下 js 中的简单语法,例如 数组语法:
js 中数组源代码为:
[1]
[1, 2, 3]
[1, 2, 3, ]
用 bnf 表示:
一个元素
ARRAY ::= "[" NUM "]"
多个元素
ARRAY ::= "[" NUM ("," NUM)* "]"
语法支持,最后一个元素右侧可以有逗号
ARRAY ::= "[" NUM ("," NUM)* (",")? "]"
NUM 表示数字,合起来就是:
ARRAY ::= "[" NUM ("," NUM)* (",")? "]"
js 数组中的元素更通用来说是表达式,如果用非终结符 EXPRESSION 表示表达式,那就是:
ARRAY ::= "[" EXPRESSION ("," EXPRESSION)* (",")? "]"
EXPRESSION ::= NUM | STRING | BOOL | FUNCTION 等等,这里是举例
方括号是终结符,因为不能继续展开,非终结符需要用引号括起来。
(A)*的意思是符号序列 A 可以重复,(A)?的意思是符号 A 是可选的。
下面使用 BNF 描述一下 html 语法(简略):
源代码:
<div id="root">
<div className="layout"></div>
</div>
bnf 表示:
ELEMENT ::= "<" IDENTITY IDENTITY "=" STRING ">" ELEMENT "<" "/" IDENTITY ">"
注意到这个语法 BNF 是一个递归推导。在含有递归的语法中,不能出现左递归(包括间接左递归),也不能有二义性,没有左递归且没有二义性的语法符合 LL(1)文法,就可以使用递归下降分析法解析。左递归无法使用递归下降分析的原因是会让程序死循环,具体可以参考编译原理龙书 2.4.5 Left Recursion 章节。
3. 递归下降分析
符合 LL(1)文法的语法可以使用递归下降分析法解析。画出上面提到 html 语法 bnf(产生式)的展开图:
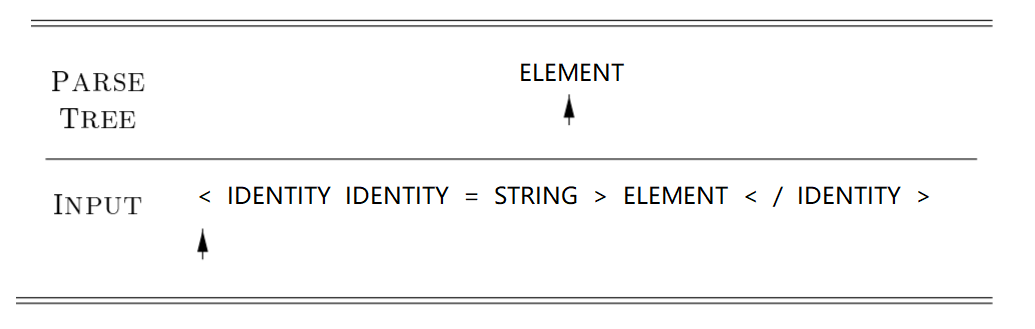
程序将从输入代码字符串从左向右扫描,预测识别为非终结符 ELEMENT,开始解构展开,扫描展开式中的符号,遇到子节点中的下一个非终结符 ELEMENT 时,递归执行解析器。这个过程就是递归下降分析,也叫预测分析。
使用伪代码描述上述递归下降分析过程:
function ELEMENT() {
match('<')
match(IDENTITY)
match(IDENTITY)
match('=')
match(STRING)
match('>')
ELEMENT() // 递归
match('<')
match('/')
match(IDENTITY)
match('>')
}
match 函数每执行一次,扫描器指针就向右移动到下一个符号。
这个过程中可以收集扫描到的符号整理成一个 ast 节点:
function ELEMENT() {
let tagName
const props = {}
let children
match('<')
tagName = match(IDENTITY)
props.key = match(IDENTITY)
match('=')
props.value = match(STRING)
match('>')
children = ELEMENT()
match('<')
match('/')
match(IDENTITY)
match('>')
return {
tagName,
props,
children,
}
}
这样当 ELEMENT 解析器执行完成后,得到的就是一个 ast 节点树了。
ELEMENT 这个解析器有点复杂,还可以进一步拆分, 例如将 props 部分拆出来作为一个 props 解析器:
function PROPS() {
let key
let value
key = match(IDENTITY)
match('=')
value = match(STRING)
return {
key,
value,
}
}
然后组合到 ELEMENT 解析器中:
function ELEMENT() {
let tagName
let props
let children
match('<')
tagName = match(IDENTITY)
props = PROPS() // 使用props解析器
match('>')
children = ELEMENT()
match('<')
match('/')
match(IDENTITY)
match('>')
return {
tagName,
props,
children,
}
}
props 可能是可选的,所以可以设计一个 option 操作符应对没有 props 的 html 标签:
function optional(term: Function) {
let fallback = index // 记录当前扫描器位置
try {
return term() // 尝试预测解析
} catch (error) {
current = input.slice(fallback) // 预测解析失败,回滚上一次分析位置
}
}
然后使用:
function ELEMENT() {
let tagName
let props
let children
match('<')
tagName = match(IDENTITY)
props = optional(PROPS) // 可选的props
match('>')
children = ELEMENT()
match('<')
match('/')
match(IDENTITY)
match('>')
return {
tagName,
props,
children,
}
}
上面的 PROPS、ELEMENT、optional 其实就是函数组合,将大的 parser 拆分为更小的 parser,由每个小的语法单元的 parser 组成最终的 完整语法 parser。
4. Parser Combinators
编译器开发中有两个流派,自底向上和自顶向下,递归下降分析就是属于自顶向下分析。上述代码中发现 match 函数、optional 等函数是固定可以封装起来的,封装起来的库就是 parsec 库,即 Parser Combinators,你只需要编写每个语法单元的 parser,然后利用 parsec 库组合起来,就是一个完整的语法解析程序。下面介绍一个使用 typescript 编写的 parsec 库:typescript-parsec
yarn add typescript-parsec
现在将上面的 js 代码使用 parsec 库翻译一遍:
首先实现 match 函数,
import { buildLexer } from 'typescript-parsec'
enum TokenKind {
word,
notWord,
}
const lexer = buildLexer([
[true, /^\w+/g, TokenKind.word],
[true, /^\W/g, TokenKind.notWord],
])
lexer 就是一个扫描字符串的函数,利用正则匹配识别非空字符和空字符
然后实现 PROP 解析器:
import { apply, rule, seq, str, tok } from 'typescript-parsec'
const PROP = rule<TokenKind, { key: string; value: string }>()
// 对应源代码:word="word"
PROP.setPattern(
apply(
seq(tok(TokenKind.word), str('='), str('"'), tok(TokenKind.word), str('"')),
([_key, _eq, _quote1, _value, _quote2]) => ({
key: _key.text,
value: _value.text,
})
)
)
tok 函数用来表示一个正则匹配的终结符解析器,例如一个单词的 parser:
tok(TokenKind.word)
str 类似, tok 函数使用的是正则匹配
seq 函数用来组合一组有序的 parser:
// word="word"
seq(tok(TokenKind.word), str('='), str('"'), tok(TokenKind.word), str('"'))
apply 函数用来将 token 序列整理为一个 ast 节点, 例如:
// seq收集到的是 [word, word], 在第二个函数参数可以拿到
apply(seq(tok(TokenKind.word), tok(TokenKind.word)), ([token1, token2]) => ({
key: token1.text,
value: token2.text,
}))
实现 ELEMENT 解析器:
ELEMENT.setPattern(
apply(
seq(
str('<'),
tok(TokenKind.word),
str(' '),
PROP,
str('>'),
opt(ELEMENT),
str('<'),
str('/'),
tok(TokenKind.word),
str('>')
),
([
_lt,
_tagName,
_space,
_props,
_gt,
_children,
_lt2,
_slash,
_tagName2,
_gt2,
]) => ({
tagName: _tagName.text,
props: _props,
children: _children,
})
)
)
这时会发现,seq 中的好多字符是没用的,导致 apply 后面函数参数太多,这时候 parsec 的特殊函数出现了:
例如 PROP 解析器中,"="符号和'"'符号是没用的:
PROP.setPattern(
apply(
seq(tok(TokenKind.word), str('='), str('"'), tok(TokenKind.word), str('"')),
// _eq, _quote1, _quote2没用
([_key, _eq, _quote1, _value, _quote2]) => ({
key: _key.text,
value: _value.text,
})
)
)
可以利用 kmid 和 kright 对 seq 序列进行简化:
import { kleft, kmid } from 'typescript-parsec'
PROP.setPattern(
apply(
seq(
// kleft表示只取左边的token
kleft(tok(TokenKind.word), str('=')),
// kmid表示只取中间的token
kmid(str('"'), tok(TokenKind.word), str('"'))
),
// 这样函数参数就只剩下两个有用的token了
([_key, _value]) => ({
key: _key.text,
value: _value.text,
})
)
)
最后,ELEMENT 解析器编写好了,还需要两个函数处理下就得到最后 ast 了:
import { expectEOF, expectSingleResult } from 'typescript-parsec'
export function parse(input: string) {
return expectSingleResult(expectEOF(element.parse(lexer.parse(input))))
}
expectEOF 用来检查 parser 是否左递归,避免造成死循环,expectSingleResult 用来检查语法二义性避免出现两个结果。
这样 html 解析器就写好了,使用它来解析文本:
const ast = parse('<div class="root" ><span id="text" ></span></div>')
console.log(ast)
结果:
{
"tagName": "div",
"props": [
{
"key": "class",
"value": "root"
}
],
"children": [
{
"tagName": "span",
"props": [
{
"key": "id",
"value": "text"
}
],
"children": []
}
]
}
除了上面用到的seq、opt、kleft、kmid,还有一些其他的操作符例如list_sc、alt、rep
list_sc用来表示被一个符号分隔的一组符号,例如描述一个数组:
// [1,2,3]
seq(str('['), list_sec(EXPRESSION, str(',')), str(']'))
// [1,2,3,] 后面加一个可选的逗号
seq(str('['), list_sec(EXPRESSION, str(',')), opt(str',') str(']'))
alt用来表示bnf中的竖杠|符号,例如描述表达式EXPRESSION:
// EXPRESSION ::= NUMBER | STRING | BOOLEAN | FUNCTION
const EXPRESSION = alt(NUMBER, STRING, BOOLEAN, FUNCTION)
rep用来描述一个重复的符号,对应bnf中的(A)*,例如描述一个程序,程序由多个语句组成:
// PROGRAM ::= (STATEMENT)*
const PROGRAM = req(STATEMENT)
5. 最后
使用 BNF 描述语法,然后按照 BNF 编写 语法单元 parser,最后将 parser 组合起来成为完整的 parser,这就是 Parser Combinators。
应用价值:
- 在编写 BNF 的时候,可以更好的理解编程语言语法设计理念。有助于写出能够被编译器优化的语法。
- 可以设计自己的语法,然后利用 parser 解析为 ast,再翻译到 JavaScript 或其他语言。例如实现 DSL 语法。
- 静态文本处理,对于一些有语法规则的文本,可以编写一个 parser 来处理它,如文本搜索,代码重构等。
6. 附录
- 1. 上述代码仓库链接:https://github.com/Saber2pr/html-parser-demos
参考
- [1]. Compilers: Principles, Techniques, and Tools - 2.4 Parsing
- [2]. ts-parsec https://github.com/microsoft/ts-parsec