1. Preface
This article will start with context-free grammars, from using BNF to describe syntax to understanding the idea of recursive descent analysis, and finally implement a simple html parser wrap-up. The highlight of this article is to write a combinatorial sub-compiler in typescript, which is of great significance and value to some specific areas of front-end development. At the same time, this article focuses on practical value, combined with a short js code example to help understand.
two。 Bakos Paradigm-Grammar description language
Backus Normal Form, abbreviated as BNF, is a language used to express context-free grammars. Each line of BNF is a derivation rule (production) in the format:
<符号> ::= <表达式>
where
STRING ::= '"' TEXT '"'
| "'" TEXT "'"
A string can be in double or single quotation marks. STRING on the left is a non-terminal character, the quotation marks on the right "is a terminal character, and TEXT is a non-terminal character because it can continue to expand, for example:
TEXT ::= (letter | digit)*
Each non-Terminator can be replaced by a sequence of symbols on the right, that is, context-free. Symbols that never appear at the left end are called Terminators.
Use BNF to describe the simple syntax in js, such as array syntax: The array source code in js is:
[1]
[1, 2, 3]
[1, 2, 3, ]
Expressed as bnf:
一个元素
ARRAY ::= "[" NUM "]"
多个元素
ARRAY ::= "[" NUM ("," NUM)* "]"
语法支持,最后一个元素右侧可以有逗号
ARRAY ::= "[" NUM ("," NUM)* (",")? "]"
NUM represents a number, which adds up to:
ARRAY ::= "[" NUM ("," NUM)* (",")? "]"
The element in the js array is more generally an expression. If the expression is represented by the non-Terminator EXPRESSION, it is:
ARRAY ::= "[" EXPRESSION ("," EXPRESSION)* (",")? "]"
EXPRESSION ::= NUM | STRING | BOOL | FUNCTION 等等,这里是举例
Square brackets are terminators because you cannot continue to expand, and non-terminators need to be enclosed in quotation marks.
(A) * means that the symbol sequence A can be repeated, and (A)? means that the symbol An is optional.
Use BNF to describe the html syntax (abbreviated): Source code:
<div id="root">
<div className="layout"></div>
</div>
Bnf says:
ELEMENT ::= "<" IDENTITY IDENTITY "=" STRING ">" ELEMENT "<" "/" IDENTITY ">"
Notice that the syntax BNF is a recursive derivation. In the grammar with recursion, there can be neither left recursion (including indirect left recursion) nor ambiguity. If the grammar without left recursion and no ambiguity conforms to LL (1) grammar, recursive descending parsing can be used. The reason why left recursion cannot use recursive descent analysis is that it will make the program loop. For more information, please refer to the compilation principles of Dragon Book 2.4.5 Left Recursion.
3. Recursive descent analysis
Grammars that conform to LL (1) grammars can be parsed using recursive descending parsing. Draw an unfold diagram of the html syntax bnf (production) mentioned above:
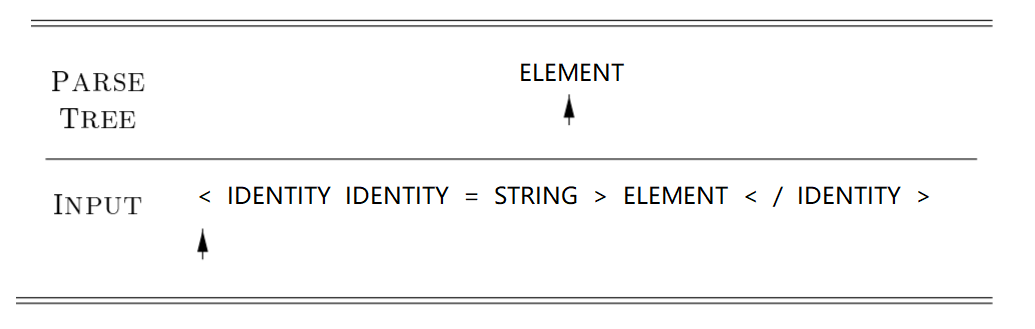 The program scans the input code string from left to right, predicts and recognizes it as the non-Terminator ELEMENT, starts deconstructing and unwrapping, scans the symbols in the expansion, and recursively executes the parser when it encounters the next non-Terminator ELEMENT in the child node. This process is called recursive descent analysis, also known as predictive analysis.
Use pseudo code to describe the above recursive descent analysis process:
The program scans the input code string from left to right, predicts and recognizes it as the non-Terminator ELEMENT, starts deconstructing and unwrapping, scans the symbols in the expansion, and recursively executes the parser when it encounters the next non-Terminator ELEMENT in the child node. This process is called recursive descent analysis, also known as predictive analysis.
Use pseudo code to describe the above recursive descent analysis process:
function ELEMENT() {
match('<')
match(IDENTITY)
match(IDENTITY)
match('=')
match(STRING)
match('>')
ELEMENT() // 递归
match('<')
match('/')
match(IDENTITY)
match('>')
}
Each time the match function is executed, the scanner pointer moves to the right to the next symbol. During this process, the scanned symbols can be collected and organized into an ast node:
function ELEMENT() {
let tagName
const props = {}
let children
match('<')
tagName = match(IDENTITY)
props.key = match(IDENTITY)
match('=')
props.value = match(STRING)
match('>')
children = ELEMENT()
match('<')
match('/')
match(IDENTITY)
match('>')
return {
tagName,
props,
children,
}
}
So when the ELEMENT parser is finished, you get a tree of ast nodes. The ELEMENT parser is a bit complex, and you can split it further, such as splitting the props portion as a props parser:
function PROPS() {
let key
let value
key = match(IDENTITY)
match('=')
value = match(STRING)
return {
key,
value,
}
}
Then combine it into the ELEMENT parser:
function ELEMENT() {
let tagName
let props
let children
match('<')
tagName = match(IDENTITY)
props = PROPS() // 使用props解析器
match('>')
children = ELEMENT()
match('<')
match('/')
match(IDENTITY)
match('>')
return {
tagName,
props,
children,
}
}
Props may be optional, so you can design an option operator to deal with html tags without props:
function optional(term: Function) {
let fallback = index // 记录当前扫描器位置
try {
return term() // 尝试预测解析
} catch (error) {
current = input.slice(fallback) // 预测解析失败,回滚上一次分析位置
}
}
Then use:
function ELEMENT() {
let tagName
let props
let children
match('<')
tagName = match(IDENTITY)
props = optional(PROPS) // 可选的props
match('>')
children = ELEMENT()
match('<')
match('/')
match(IDENTITY)
match('>')
return {
tagName,
props,
children,
}
}
The above PROPS, ELEMENT, and optional are actually function combinations that split large parsers into smaller parsers, and the parsers of each small syntax unit form the final complete syntax parser.
4. Parser Combinators
There are two schools in compiler development, bottom-up and top-down, and recursive descent analysis belongs to top-down analysis. The above code found that match functions, optional and other functions are fixed can be encapsulated, the packaged library is the parsec library, that is, Parser Combinators, you only need to write the parser of each syntax unit, and then use the parsec library to combine, is a complete syntax parser. Here is a parsec library written in typescript: typescript-parsec
yarn add typescript-parsec
Now translate the above js code using the parsec library: First implement the match function
import { buildLexer } from 'typescript-parsec'
enum TokenKind {
word,
notWord,
}
const lexer = buildLexer([
[true, /^\w+/g, TokenKind.word],
[true, /^\W/g, TokenKind.notWord],
])
Lexer is a function that scans strings and uses regular matching to identify non-empty characters and empty characters. Then implement the PROP parser:
import { apply, rule, seq, str, tok } from 'typescript-parsec'
const PROP = rule<TokenKind, { key: string; value: string }>()
// 对应源代码:word="word"
PROP.setPattern(
apply(
seq(tok(TokenKind.word), str('='), str('"'), tok(TokenKind.word), str('"')),
([_key, _eq, _quote1, _value, _quote2]) => ({
key: _key.text,
value: _value.text,
})
)
)
The tok function is used to represent a regular matching Terminator parser, such as the parser of a word:
tok(TokenKind.word)
str is similar, the tok function uses regular matching The seq function is used to assemble an ordered set of parsers:
// word="word"
seq(tok(TokenKind.word), str('='), str('"'), tok(TokenKind.word), str('"'))
The apply function is used to organize the token sequence into an ast node, for example:
// seq收集到的是 [word, word], 在第二个函数参数可以拿到
apply(seq(tok(TokenKind.word), tok(TokenKind.word)), ([token1, token2]) => ({
key: token1.text,
value: token2.text,
}))
Implement the ELEMENT parser:
ELEMENT.setPattern(
apply(
seq(
str('<'),
tok(TokenKind.word),
str(' '),
PROP,
str('>'),
opt(ELEMENT),
str('<'),
str('/'),
tok(TokenKind.word),
str('>')
),
([
_lt,
_tagName,
_space,
_props,
_gt,
_children,
_lt2,
_slash,
_tagName2,
_gt2,
]) => ({
tagName: _tagName.text,
props: _props,
children: _children,
})
)
)
At this time, you will find that many characters in seq are useless, resulting in too many function parameters after apply. At this time, the special function of parsec appears: For example, in a PROP parser, the "=" symbol and the "" symbol are useless:
PROP.setPattern(
apply(
seq(tok(TokenKind.word), str('='), str('"'), tok(TokenKind.word), str('"')),
// _eq, _quote1, _quote2没用
([_key, _eq, _quote1, _value, _quote2]) => ({
key: _key.text,
value: _value.text,
})
)
)
Seq sequences can be simplified using kmid and kright:
import { kleft, kmid } from 'typescript-parsec'
PROP.setPattern(
apply(
seq(
// kleft表示只取左边的token
kleft(tok(TokenKind.word), str('=')),
// kmid表示只取中间的token
kmid(str('"'), tok(TokenKind.word), str('"'))
),
// 这样函数参数就只剩下两个有用的token了
([_key, _value]) => ({
key: _key.text,
value: _value.text,
})
)
)
Finally, the ELEMENT parser is written, and two more functions are needed to get the final ast:
import { expectEOF, expectSingleResult } from 'typescript-parsec'
export function parse(input: string) {
return expectSingleResult(expectEOF(element.parse(lexer.parse(input))))
}
ExpectEOF is used to check whether parser is left recursive to avoid causing a dead loop, and expectSingleResult is used to check syntax ambiguity to avoid two results. So the html parser is ready to use it to parse the text:
const ast = parse('<div class="root" ><span id="text" ></span></div>')
console.log(ast)
Results:
{
"tagName": "div",
"props": [
{
"key": "class",
"value": "root"
}
],
"children": [
{
"tagName": "span",
"props": [
{
"key": "id",
"value": "text"
}
],
"children": []
}
]
}
In addition to the seq, opt, kleft and kmid used above, there are some other operators such as listsc, alt, rep Listsc is used to represent a set of symbols separated by a symbol, such as describing an array:
// [1,2,3]
seq(str('['), list_sec(EXPRESSION, str(',')), str(']'))
// [1,2,3,] 后面加一个可选的逗号
seq(str('['), list_sec(EXPRESSION, str(',')), opt(str',') str(']'))
alt is used to indicate the vertical bar in bnf| Symbols, such as descriptive expressions EXPRESSION:
// EXPRESSION ::= NUMBER | STRING | BOOLEAN | FUNCTION
const EXPRESSION = alt(NUMBER, STRING, BOOLEAN, FUNCTION)
Rep is used to describe a repeated symbol corresponding to (A) * in bnf, for example, to describe a program, which consists of multiple statements:
// PROGRAM ::= (STATEMENT)*
const PROGRAM = req(STATEMENT)
5. Last
Use BNF to describe the syntax, then write the syntax unit parser according to BNF, and finally combine the parser into a complete parser, which is Parser Combinators. Application value:
- When writing BNF, you can better understand the design concept of programming language syntax. Helps to write syntax that can be optimized by the compiler. two。 You can design your own syntax, then parse it to ast using parser, and then translate it to JavaScript or other languages. For example, implement the DSL syntax.
- Static text processing, for some text with syntax rules, you can write a parser to deal with it, such as text search, code refactoring and so on.
6. Appendix
-1. Link to the above code repository: https://github.com/Saber2pr/html-parser-demos
reference
[1]. Compilers: Principles, Techniques, and Tools-2.4Parsing -[2]. Ts-parsec https://github.com/microsoft/ts-parsec